Can coding agents build complex systems?

Or, put another way, can you vibe code a database server?
AI coding agents can help make progress on a range of problems. But how good are they at building and architecting a complex project such as a relational database server that can run SQL?
Imagine the query SELECT email FROM users; A lot needs to happen for a database to be able to run it. First it needs to be parsed into a format that can be executed. Next the query needs to be validated to make sure the column and table exists. Lastly the query will be executed which includes loading data from a storage engine and returning it. More complex queries will also need to validate the type of expressions and resolve references, as well as filter, group, join and aggregate data.
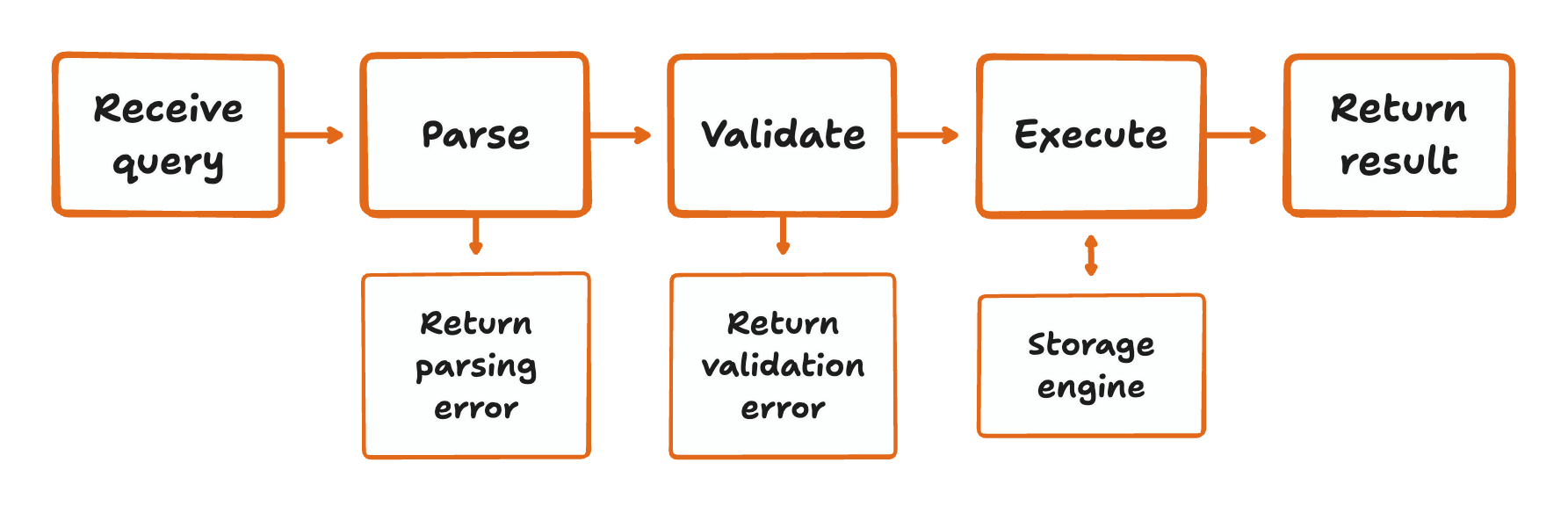
These layers of complexity makes building a database a useful project to use to evaluate autonomous coding agents.
Guiding the agent
For my book, Build a Database Server, I created a test suite made up of hundreds of SQL statements to guide readers through building a database. The test suite starts with testing simple queries such as SELECT 1; and gradually progresses to statements that can store, filter, join and group data.
The coding agent can use the same test suite to guide and validate its implementation.
I want to give the coding agent the best chance of success. As well providing tests I have:
- Chosen a problem which already has many implementations and plenty of literature written about it. Presumably, the source code for existing relational databases were part of the agent’s training data.
- Provided a CLAUDE.md file for the agent, as suggested by Claude Code’s Best practices for agentic coding.
- Explicitly prompted the agent to refactor to improve the code it’s written after every test file to mirror the process I went through when creating my own implementation.
I will be asking the agent to use Ruby for its implementation. While databases are often written in system programming languages such as C and C++, I’m more interested in the architecture of the system it creates than the performance of the database. Using Ruby will let me compare the code it generates to my own implementation.
Running the agent
My first task was to create a CLAUDE.md file that documented the project and contains general instructions.
During a test run of the agent, I found that the agent didn’t write what I consider to be ‘good quality’ code by default - it created long methods that were hard to follow, and introduced redundant comments. I decided to be more explicit about code style and updated it to add the following:
- Write understandable and maintainable code
- Try to organize code into smaller methods
- Prefer self documenting code with descriptive methods and variables rather than using comments.
I also added guidance on how to refactor code and what refactors to do.
I ran Claude Code with Opus 4.1. I started each test file in a new session and used claude --permission-mode acceptEdits so the agent could edit files without needing confirmation. I then asked the agent to implement each test file with a prompt:
Add to the implementation so the 2_returning_values.sql tests pass
After the implementation was complete, I asked the agent to refactor:
Make any refactors that improve the code. The 3_tables.sql file and subsequent tests aren’t passing yet so it’s fine if they fail, do not try to make them pass.
You can see all of the code that the agent produced and compare it to my sample implementation.
Agent strengths
Here’s what I found the agent to be good at:
Making progress
Claude code was always able to make progress and get the tests passing. Impressively, it did this without needing any additional prompting for each test file and wrote code faster than I could.
As the project requirements and complexity grew, it did take longer to implement the functionality needed for a test file to pass. The agent was also more likely to introduce regressions, but it was always able to get to a green test suite.
Debugging
Whenever there was a failing test or unexpected behaviour the agent was able to hammer away at the problem until it was fixed.
From seeing its actions, it’s clear that it didn’t try to reason about the state of the executing code that caused the error. Instead it made a guess based on the code and the error. If a fix didn’t work it often created a script to try to reproduce and narrow down the problem or added logging.
A criticism about debugging is that the agent would have saved time and reduced token usage if it invested time to make debugging the code easier in general. It could have done this by removing overly broad rescue statements, introducing lower level tests, or adding debug logging that could be toggled when needed.
Agent weaknesses
Here’s what I found the agent to be bad at:
Following instructions
I added some more specific instructions to try to get the agent to improve code quality including “Try to organize code into smaller methods” and “Prefer self documenting code with descriptive methods and variables rather than using comments.”. I’ve no evidence that this had an effect. While variables and methods are generally descriptive, there are plenty of long methods and 100s of redundant comments that just describe the code on the following line
When I asked it to create separate commits for each refactor and it didn’t I tried to be more forceful - ‘You MUST create a DIFFERENT commit for each refactor. Do NOT put multiple refactors in a single commit’. This worked to a point. I did catch the agent working on many refactors before committing and then retroactively trying to create separate commits for them.
My take away from this is that any instruction you care about must be confirmed by another system and you can’t rely on instructions alone to define a specific workflow.
Producing high quality code
I wasn’t impressed by the quality of the code produced. It’s so important that the code written by agents is easy to understand and change so that humans can review and change it.
If I was trying this again I would introduce a linting tool such as Rubocop to prevent certain problems. This isn’t ideal as linting tools aren’t always right and a human engineer can reason about errors from a linter and when to ignore it, something that I’m not sure the agent will be able to do.
As well as long methods and redundant comments, I spotted other issues that would make the code harder to work with. For example:
- Having a broad ‘rescue’ statement in parser that caught any standard application errors rather than specifically defined errors. This can mask real issues and make the code harder to debug. This even tripped up the agent itself when valid statements caused parsing errors and it wasn’t clear why.
- A complex SELECT parser that was hard to understand and extend. Regular expressions are a useful tool for parsing, but I found the way the agent used them in a way that was hard to follow as it produced complex regular expressions with multiple capture groups. There were separate checks to make sure the remaining input didn’t include keywords. Looking at the code, I don’t trust it to be able to parse slight variations of statements outside of the test suite that might have different combinations of keywords and whitespace, or not to be susceptible to SQL injections.
- Lack of validation and safety. The used hashes to store constants and the abstract syntax tree. In Ruby, looking up a key in a hash that doesn’t exist returns
nilwhich can make it easy to introduce errors that are hard to debug. It’s common to usefetchwhen you expect a certain key to exist or useData,Structor other classes to define objects with specific attributes.
Creating abstractions and APIs
To show a concrete example of all of them, let’s look at the parsing of a LIMIT and OFFSET values from a SELECT statement. Here’s the code I wrote to parse the keywords and values:
limit = parse_expression if statement.consume(:keyword, 'LIMIT')
offset = parse_expression if statement.consume(:keyword, 'OFFSET')
When I wrote my implementation, I introduced a tokenizer so that there was a single place that would handle different capitalization and whitespace. I also created a way for the parser to ‘consume’ the next token which is something it would need to do many times.
In contrast, the agent created a 85 line method for parsing LIMIT and OFFSET expressions. The method broadly has the same functionality as the one I wrote, but because there is no tokenizer or statement object it has to handle varying whitespace, different cases of keywords, missing expressions and reaching the end of the statement. All of these concerns make the method harder to understand and modify.
For some aspects of code you can set up linters and code analysis tools to provide feedback loops for agents. Creating feedback loops to encourage well abstracted code with clear APIs is difficult since you can only measure it indirectly through other metrics. When I tweaked the prompt to encourage it, I found it caused the agent to move code into different files without creating clear boundaries and abstractions. Some of the abstractions the agent did create were applied inconsistently or were confusing, for example:
- The agent created a tokenizer to help with parsing but this was only used for expressions and the parser and tokenizer were in the same class with no clear separation between them.
- The agent introduced a QueryPlanner class. This class validated the query and processed column names and aliases to make them easier to work with, but it didn’t do the core task of a query planner which is to decide how to execute the query.
Leaving dead code
When reviewing the code that the agent produced, I noticed there was a lot of dead code. I used the coverband tool to find 500 lines of code that were in methods that didn’t run during the test suite and were never called in the codebase. 500 lines is a significant proportion of the total project - just over 10%.
Looking at the changes, many of the lines were introduced as part of refactors but never used, or were made redundant by refactors but not cleaned up. For example, the commit that introduced the AggregateFunction class added a validate_function method and three other methods that were never used.
I also found further code that was never run during the test suite, but might be called for certain inputs. I thought that writing the tests myself would allow me to validate the behaviour of the system the agent creates. However, since the agent had a tendency to implement behaviour not in the tests the project has undefined and untested behaviour which would be a risk if deployed.
Can a coding agent build a database system?
Yes, but not one I trust or would want to maintain.
For the tested functionally the agent was able to create a working implementation, but I wasn’t happy with the quality of it. By investing time creating more feedback loops around code quality and test coverage the agent would likely perform better, but I do not believe it would be able to consistently write high quality code containing good abstractions and APIs.
I looked at the size of the codebase after each test file was passing in my implementation compared to the agents. Lines of code alone isn’t a good way to judge codebases, but here it shows how the projects grew relative to each other. Because the agent wasn’t able to create re-usable abstractions, the size of the codebase grew at a faster rate than the one I created (the dead code and excessive comments explain 25% of the difference).
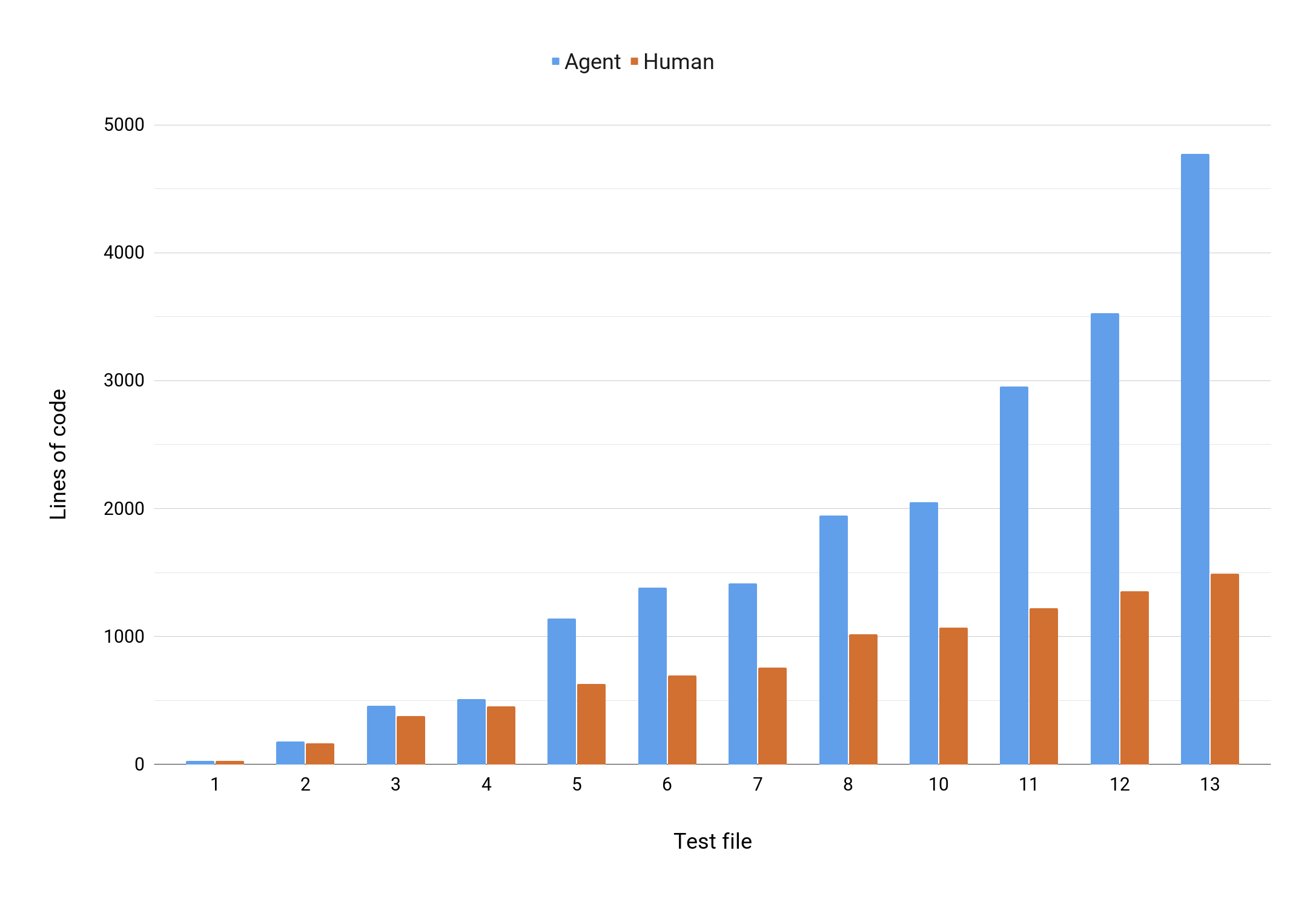
The growing codebase caused problems for the agent too - each test file took longer to implement and required more lines of code to do it. I also saw more unexpected test failures that needed more cycles to debug.
If you are working on an isolated problem or a throw-away prototype then an agent might be able to deliver something quickly, but if you are building anything bigger in the short term the speed will come at the cost of maintainability.
Given that building complex systems is still something we as humans need to do, you might find my book useful - Build a Database Server. As well as learning about how real world databases work, it’s a great way to practise architecting a system and the book contains ideas for abstractions and refactors that can help.
